[ Text of the paper: Please scroll up to see the full text ]
Prosodic Structure - Speech Signal Block Coding
tinyimin Nanjing China ; 18260060980@163.com
Do you like the music,and understand the relations between seven Nodes “CDEFGAB”. Ancient Greece Pythagoras said: Four degree five degree sounds are nature sounds under universe, therefore we study to this magical Prosodic Structure .
[Main Text]:
 1. The Prosodic Structure 1. The Prosodic Structure
The Prosodic Structure is a data relation structural, called " PS ",and it is a block coding way for Speech Signal too.
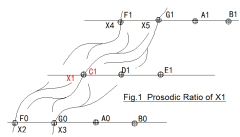
1.1 The Prosodic Ratio and Prosodic Network (See Fig.1)
In the positive real number domain, assume: X1 is a any point ,then ,always have four point X2, X3, X4, X5, that to X1 ,the Ratio of their numerical values is [2/3, 3/4, 4/3, 3/2], that called "Prosodic Ratio" or "Four_way Ratio", these four points are called "Four-way point" of X1. Between them is “Prosodic Relations” or called “Prosodic Correlation”, it is two-way (See Fig.1). Similarly, these four points respectively have four points that with it are Prosodic Relations too. Similarly ....It is easy to prove that, by the “Prosodic Ratio”, these Prosodic Relations points are convergence at the same Network, that called "Prosodic Network” or "pW ".
In the field of positive real numbers, there are many pW's co-exist logically, and they are all similar.
The points collection in a prosodic area(PA) of the Prosodic Structure(PS), is understood by human consciousness as music."there are Prosodic Structures in human consciousness!"
1.2 Prosodic Area and Music (See Fig_2)
In the prosodic network naturally form prosodic Area one by one, that denoted as "pA" (as shown in the black dot area of Fig_2). The relationship of the nodes that in the Prosodic Area can be expressed by the following formula:
pA=[1,k,k*k,4/3,3/2,3/2*k,3/2*k*k]; (k=9/8)。
Among them, the "1" is the" base point ", denoted as "C1". When a sound Xi as the fundamental tone BF, that is C1=BF, it is called "Instantiation", and this pA is the musical point understood by humans that denoted as [CDEFGAB] (physiological reasons unknown). Therefore, pA is called the " Music Nodes Coefficient".
Human musical sense does not rely on the fundamental note C1. Sometimes, even without C1 in a piece of music, it can still recognize the musical sense of that section. From this, it can be seen that the sense of music mainly depends on the structure of the prosodic ratio between musical points.Fig.1 is a part of Fig.2.
[Description]: The short arc in the figure is expressing “Four_way Ratio” relationship (logical relationship).
I
In Fig_2, there are two red arc, which are boundary line that made by F or B. Between two boundary line is main pA of X1. In a pW, on both sides of the main Prosodic Area(pA) are “Shadow Areas” .The Shadow Areas likes Shadow of the main pA that one by one. For example, the first of the left side is "Shadow Areas -1 " (in blue arc), the first of the right side is "Shadow Areas +1" (in green arc).... Any Prosodic Area (pA) has all properties of main pA, they are similar. The Ratio of Between the adjacent pA is 3^7/2^11.
1.3 VK System(vkSy):
The auditory sense can obtain the fundamental tone BF of the speech in a short time. But auditory more emphasis on the relative comparison between the subsequent sounds, which is the prosodic ratio pA. pA can be refined into 12 points that called " Volute Knot", or simply "VK" :
VK=[pA(2:3)*2^11/3^7,pA(1:3),pA(4:7),pA(4:6)*3^7/2^11];
The upward direction are the "VK coefficient", and after sorting they are [CdDeEFfGgAaB], Obviously, the music set (pA) is a subset of the VK.
The vkSy is called "VK System": vkSy=VK*2^n; (n is an integer, it is called "n-level"). vkSy divides the spectrum into many small regions, which can be understood as the frequency region between two VK points. It can also be understood as a frequency domain of a VK point, which called the " vkPD": The frequency region from this VK point (closed region) to the next VK point (open region).
1.4 The formants of speech are closely related to the VK point domain vkPD.
For example: "Me1" is a Example of the Vowel's [e] , this is 12th time period of it. (goal peak >12.0. the max 1312 Hz(70.2) is in 9th time period):
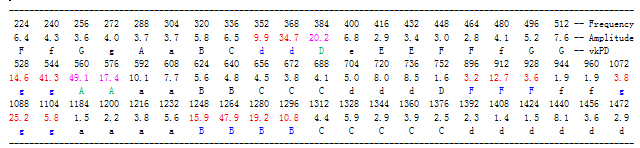
Analysis: In “ Me1” the main Formant is in close with vkPD.
IIn which, there are three main Formants: “896~928(F)”; “1072~1104(g)”; “1248~1296(B)”, that sampled by three vkPD that is F,g,B, that can writed “vkPD(F,g,B)”. In these vkPD the energy compared to their left and right sides, these vkPD are stronger a lot. In which: Three main Formant (their main part of energy) (Red) are respectively sent in the three vkPD(F,g,B)(blue); Three vkPD (F,g,B) respectively sampled the three Formants (their main part).
In other, Formant "352~368~384" is jointly sampled by two adjacent vkPD (d,D) , that formed "left hillside", "right hillside"; the Formant “528~544~576” is jointly sampled by two adjacent vkPD (g, A) , that formed "left hillside", "right hillside" too.
These sampling facts, have provided two aspects information for us: 1)The pronunciation of this Formant is generated from this "vkPD" (frequency area), this vkPD is called "goal vkPD" of this Formant (its pronounce goal); 2)These 5 main Formants (its main part) are 7 vkPD of the VK System. (These has provided important clue for follow-up study).
1.5 "Characteristic VK Point Group" (vG) of the Speech unit
In the VK System (vkSy), there are "Characteristic VK Point Group" that denoted as "vG". Here, only two vowels [a] [ao] are used to explain this vG. (They only roughly indicate the direction and methods of the research. The data needs to be optimized and deepened)
1.5.1 Vowel [a]: First, let's look at its example one " za7". The next line extracts the main frequency-domain signals of its 57th and 59th time periods: (This article only analyzes the relationship among the first few stronger frequency points in the frequency domain signal. Using the autocorrelation BF=204Hz)

At frame 57, [832 (27.5), 1040(41.9), 1248(48.9), 1456(25.1)] the greatest common divisor of this four strong points is 208. Obviously, all these four points accurately bind the relationship of BF*[4,5,6,7]! (Where BF=208)
At frame 59, [848 (23.3), 1056(40.5), 1264(41.8), 1472(19.5)] the GCD is 211Hz, and 224(46.9) rose to the strongest, it can be seen that the fundamental tone is rising: 204-208-211-224. However, the relationship among the four points remains unchanged: "Grouping together": Try to maintain the multiple relationship with the fundamental tone as much as possible: BF * [4,5,6,7].
The "Characteristic VK Point Group" (vG)of vowels [a] is vG(a)=BF * [4,5,6,7]; In this example, they are several multiple homophones. However, the expression of the vowel [a] is not always like this; most of them present An "arithmetic sequence" relationship: An=A1+D*(n-1); D is the tolerance that closed to the BF.
Let's take a look at "Ma2" that second example of the vowel [a], at frame 34:
(BF=320Hz,KF=150Hz)
[
The tolerance of the four strong VK points (red: e, f, A, B) is approximately 160Hz. It is worth noting that there is an error in the frequency number, but it is contained by the VK domain(Rough). In fact, the above equation BF * [4,5,6,7] is a special case of the arithmetic sequence.
1.5.2 Compound Vowels [ao], for example, "oao2", 20th frame of it:
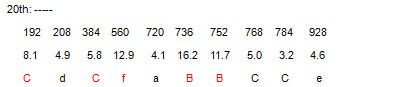
The relationship among the four red VK dots is:
vG(ao)=[BF,BF*2, BF*2*Vk(7),BF*2*Vk(12)]; the "Characteristic VK Point Group" (vG) of the [ao] is
[C/2, C, f, B]. And the sound reconstructed with these four VK points is precisely the [ao] sound.
(Click on "Attachments-vG" in the middle bar to view more speech examples)
2. The working principle of vkSy:
As can be seen from the above three cases: When we listen to speech, we mainly focus on the relationship between them! This relationship is its "characteristic VK point group(vG)".
vG is a model of each voice unit that "speaks" and "listens" with all it. "Toddler Language Learning" is actually an effort to master vG, that prosodic ratio model commonly agreed upon by the society in this region.
2.1 vkSy is composed of all levels of VK and VK points. After obtaining the Fundamental frequency, the vkSy is instantiated. And vkSy is dynamically mapped between the cochlear spiral apparatus, including the nucleus on the pathway and the auditory cortex. vkSy constantly collects and summarizes the reaction information of the voice, and transmits it to the consciousness.
vkSy is similar to a "ruler". The Compound vowel of speech is a periodic signal that is grouped and encoded by vkSy.The initial consonants are initiating sounds, composed of intermittent timbres. Initials and Finals forms rich speech.
2.2 Take a Chinese sentence as an example:
Someone was Shouting "Dao !" at the door, mother heard (noticed). The process of its acceptance is: First, sense the " initials", whose timbre indicates that it is the initial consonant "D" from the tip of the tongue. Immediately following the sound cluster, the cochlear organ clearly sensed his fundamental tone BF, the listener's vkSy is instantiated by BF (" attention ") : Its C1 is mapped to the BF position of the screw. This sound cluster is also accompanied by three periodic signals, [BF, BF*Vk(7), BF*Vk(12)] resonance occurs near the corresponding characteristic frequency position of the screw. In the mapping, vkSy immediately sensed their relationship with the BF: The symbol represented by the VK point is [C, f, B] (three VK dots). Based on the existing impression, this is the characteristic VK Point group vG of the Compound vowel [ao]. vkSy made the consciousness aware that the sound just heard was "Dao". This familiar timbre, the mother realized that it was her son who had come home! Moreover, it can be further associated with phrases that were once remembered, and even emotional stories.
Closing remarks: vkSy is at the forefront of consciousness. These phonetic impressions, that is, the content stored and remembered by the brain, are composed of a series of prosodic ratios rather than specific frequencies! These assumptions in this article are certain to exist, because humans are sensitive to and very interested in music, and music is the embodiment of vkSy (prosodic structure). Human consciousness uses prosodic structures to group and encode speech signals, used to control the speaking, listening and storage of. speech.
|
[Abstracts]:
For any point X1, there are always four points X2, X3, X4, X5, that their ratios to X1 are [2/3, 3/4, 4/3, 3/2], it is the "Prosodic Ratio", and forms a prosodic network. The prosodic network naturally forms the Prosodic Area(pA) one by one:
pA=[1,k,k*k,4/3,3/2,3/2*k,3/2*k*k] (Where k=9/8);That pA after the fundamental tone(BF) instance, is the musical point as understood by humans [CDEFGAB]. The vkSy is called "VK System" which vkSy=pA*2^n (n is an integer, it is called "n-level"). vkSy consists of a series of prosodic ratios, by which speech signals are grouped and encoded. vkSy is at the forefront of human consciousness. After the fundamental tone instantiation, vkSy is mapped onto the cochlear spirator and its pathways. In the VK System(vkSy), there are "Characteristic VK Point Group" (vG), this vG constantly summarizes and matches the voice stream, and transmits it to the consciousness. The "impression" of speech stored in the brain, is a relationship composed of a series of Prosodic Ratios rather than specific frequencies.
[Reveal]:
Prosodic Structure(PS) is a block coding way for Analog Signal. In which, VK*2^n is “VK System” that is the Block coding of speech signals. It is one way that the human consciousness group and code the audio signal. It based the Prosodic Area, and expending to VK System, that is used to control the pronunciation and listen of language. |
| Change to 中文版 |
(Click) Attachments-vG
o o o o
|
Down : Click
Count:6127
|
| Discussing (讨论区):
* 32.: The Prosodic Structure exists in human cons
ciousness. The speech signal is grouped and enco
ded by the VK System (vkSy). In the vkSy there a
re "Characteristic VK Point Group" (vG), The "im
pression" of speech stored in the brain, is a re
lationship rath...
* 31.: Speech Signal Block Coding and Vowel's VK A
ttribute
...
* 30.: [ao] =[C,C*4/3,C*3/2] =[C,F,G]....
* 29.: RyFr
...
* 28.: The mankind always wants to get the working
shape of one's own consciousness, the Prosodic
Structural Theory is its basic theory.
...
|
|
[Friendly link]: baidu bing Google |
|
